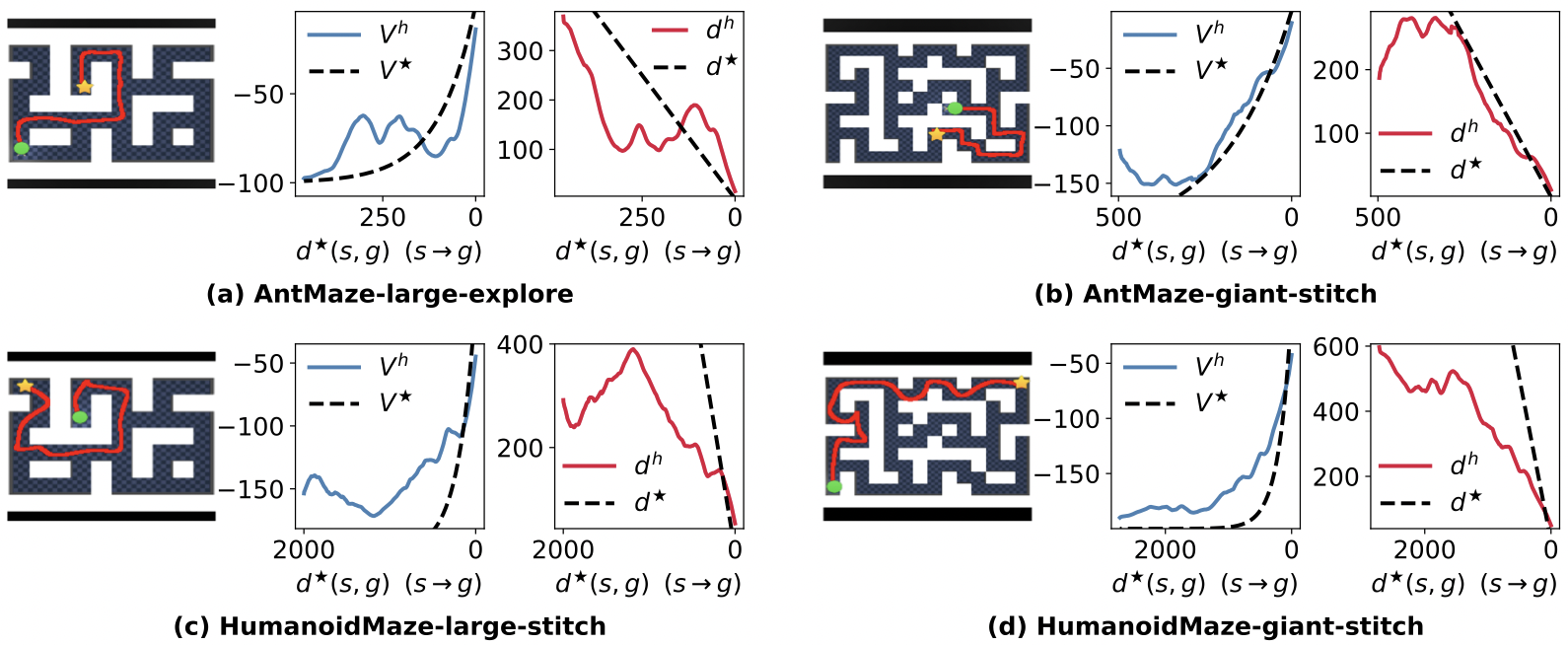
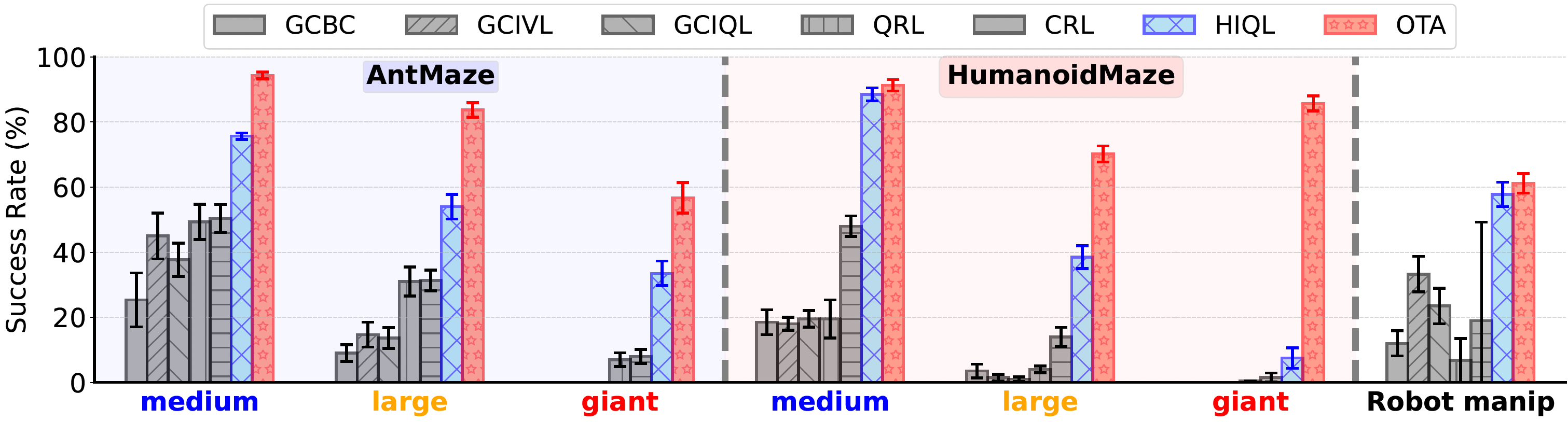
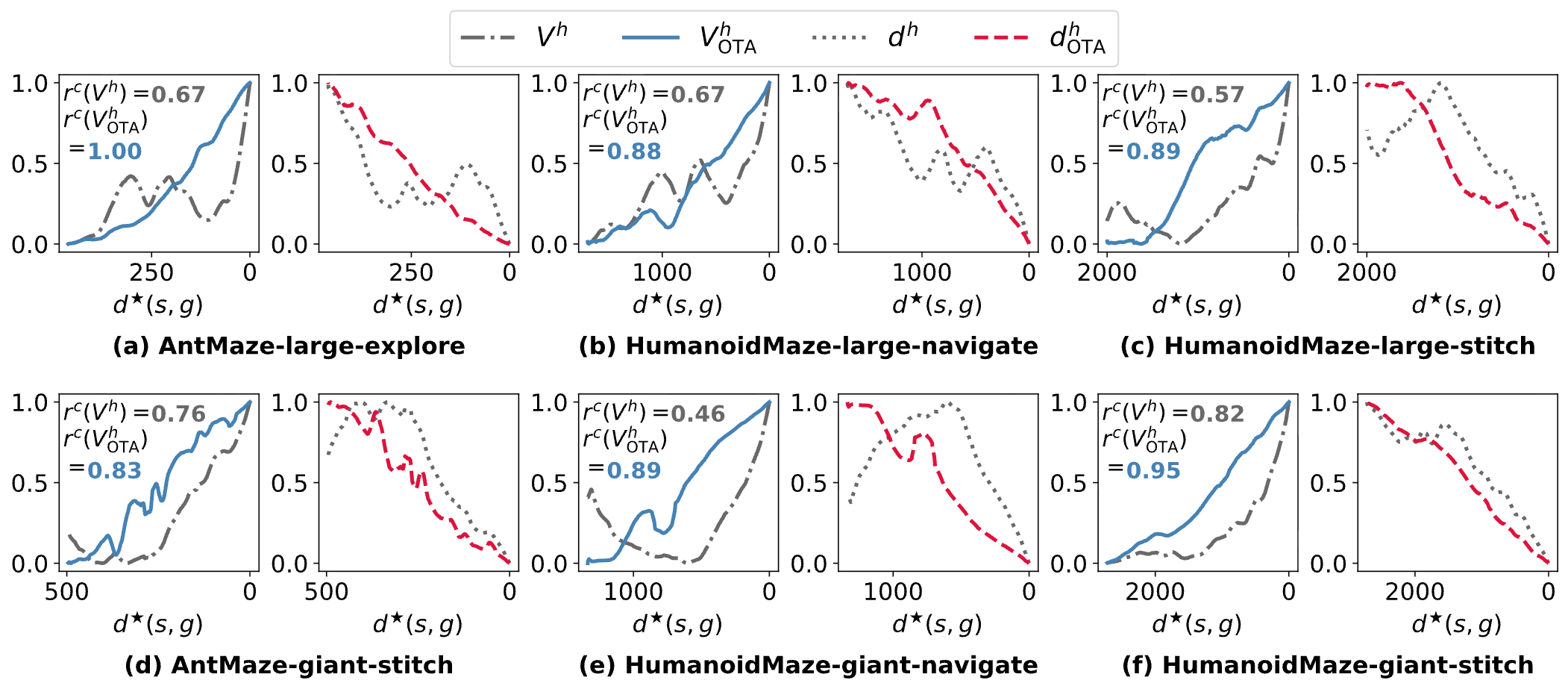
High-Level Policy is the Bottleneck of Hierarchical Policy.
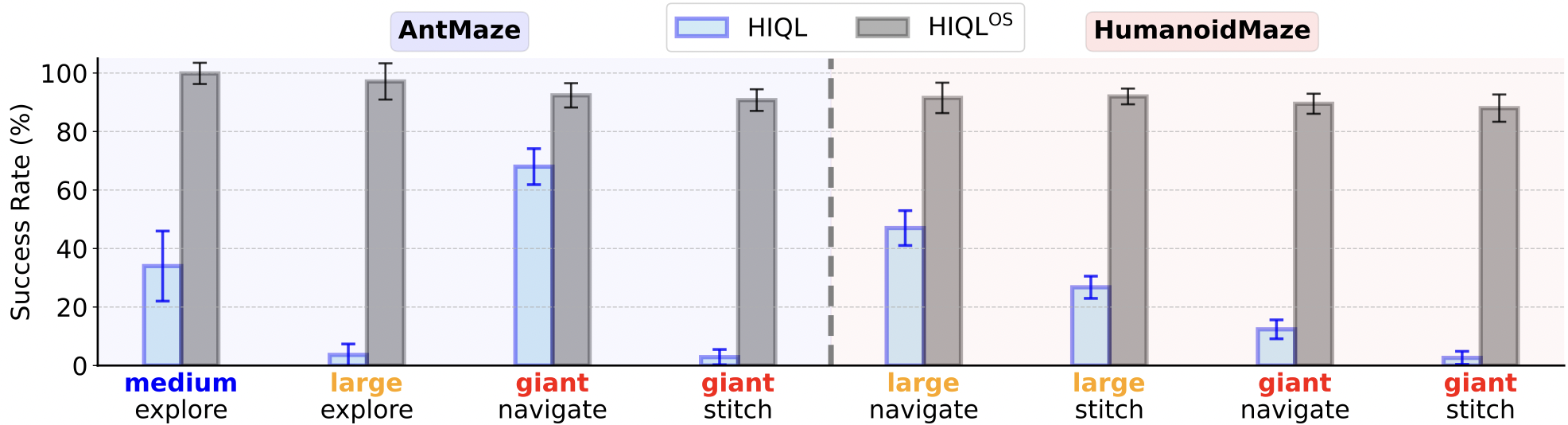
We evaluate HIQL by varying only the high-level policy while keeping the low-level policy fixed. Using learned high-level policy, performance drops, whereas using the oracle high-level policy achieves high success rates, indicating the high-level policy is the main bottleneck.